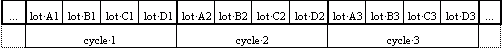
Le sujet de cette recherche, précédemment intitulée "L'intelligence artificielle appliquée à l'ordonnancement de production", nous a amené à étudier d'une part les techniques de l'intelligence artificielle et d'autre part celles de l'ordonnancement de production, afin de les marier.
Au fur et à mesure de l'avancement du projet, le sujet c'est affiné pour en arriver au nouvel intitulé "Utilisation des connaissances pour la résolution de problème d'ordonnancement de production".
Le résumé ci-après abordera directement les propositions de résolutions sans trop retracer tout l'historique ayant permis d'y arriver.
L'étude porte sur la problématique de l'ordonnancement de la production d'un carnet "dynamique" de commandes dont certaines, répétitives dans le temps, peuvent être considérées comme prévisibles ou "semi-prévisibles".
Le terme "dynamique" signifie qu'à l'arrivée de nouvelles commandes. On vérifie tout de suite si elles doivent elles doivent faire partie de l'ordonnancement en cours. Par exemples, on essayera de les intégrer à l'ordonnancement actuel si elles rentrent dans le cadre d'une campagne publicitaire actuelle, si elles correspondent à des produits faisant parties d'un cycle de production en cours ou à venir dans l'horizon d'ordonnancement.
Outre la nécessité de respecter les délais de livraison, la production doit minimiser les temps de changement d'outils (setup-time) considérés comme dépendants de la séquence - ce qui est souvent dans la pratique -.
Un autre critère, qu'on essayera de prendre en compte, est ce que nous appelerons la notion de campagne de production. Une campagne de production sera soit la nécessiter de surproduire un ou des produits en vue d'une promotion publicitaire, soit la volonter d'avoir un cycle de production pour certains produits. Ce critère de campagne de production va influencer l'ordonnancement de production en réduisant la capacité de production de certaines machines (notion de plages réservées) et/ou en fixant les dates de fabrication des produits et donc leurs délais de fabrication.
Enfin, le dernier critère dont on souhaiterait tenir compte est celui de performance des machines. Ce critère se rattache à la notion de machine parallèle. En effet, lorsqu'un produit peut être usiner sur différentes machines (machines en parallèle) ayant des rendements différents, il semble évident qu'on a toujours intérêt à utiliser la machine ayant le meilleur rendement. Un meilleur rendement revient à produire plus de produits dans un même temps ou un même nombre de produits en moins de temps. Ce gain de temps représente du temps de production disponible supplémentaire et donc la possibilité de commencer ou d'exécuter un ou plusieurs autres jobs. Un job correspond à la fabrication d'une certaine quantité d'un produit donné en vue de répondre à une commande donnée.
Pour ce qui est des temps de changement, les algorithmes actuels, bien que très performants, sont souvent dépassés par l'ampleur du travail dans des cas industriels.
Il est donc nécessaire de créer de nouveaux algorithmes d'ordonnancement basés sur d'autres méthodes de résolution ou d'utiliser d'autres techniques de résolution.
Une première voie semblant intéressante est celle de la décomposition hiérarchique des problèmes.
La décomposition hiérarchique consiste en une découpe du problème en sous problèmes à résoudre dans un ordre donné; les sous problèmes sont considérés comme indépendants si ce n'est l'ordre dans lequel ils doivent être résolus.
Lorsque les temps morts sont dus, et c'est le cas le plus fréquent, à la modification de caractéristiques techniques sur les machines pour passer d'un produit à l'autre, on remarque rapidement que pour des produits ayant des caractéristiques "semblables" les temps morts sont faibles par rapport à ceux nécessaires pour passer d'un produit à un autre ayant des caractéristiques assez voire tout à fait différentes.
De cette constatation est née l'idée de répartir les produits en "familles" à l'intérieur desquelles les produits ont des caractéristiques "identiques", ou "semblables", et donc de faibles temps morts entre eux.
Les temps morts entre familles seront eux d'un ordre de grandeur supérieur et pourront être plus ou moins grands selon l'écart entre les caractéristiques techniques les différenciant.
Cette répartition en familles devrait permettre de réduire la taille de la matrice des temps morts. En effet, au lieu de devoir connaître ces temps morts pour toutes les combinaisons de produits pris deux à deux, il n'est plus nécessaire que de connaître ceux nécessaires au passage de toutes familles à toutes autres familles.
Cette classification en familles permettrait de construire un
ordonnancement par lots, où chaque lot représentera une série
de produits d'une même famille.
Dès lors, deux types d'ordonnancement seront à déterminer,
celui des produits à l'intérieur des familles.
Le problème d'ordonnancement des familles est assez simple à résoudre lorsqu'il n'y a qu'un seul critère mais devient rapidement ardu, voire insoluble, lorsque l'on doit gérer plusieurs critères qui, pris séparément, donneraient des séquences très différentes, voire inverses.
Voici deux exemples de ce type de classification :
Cette classification en familles selon un critère technique permet souvent, dans la pratique, d'identifier assez facilement la séquence optimale d'ordonnancement des familles du point de vue minimisation des temps de changement d'outils, ainsi que la valeur de ces derniers.
De même, si l'ordonnancement à l'intérieur des familles se fait selon un critère technique, la séquence de fabrication est connue ainsi que les temps de setup entre produits d'une même famille.
Si l'ordonnancement entre familles et intra familles est connu, on est en droit de ce demander où est le problème. Pour le(s) découvrir, nous allons décomposer la démarche proposée en quatre phases.
La première phase devra définir ses familles sur base des caractéristiques techniques des produits. On peut considérer que, selon les critères retenus et surtout s'il y a un "mélange" de ceux-ci, un même produit pourrait entrer dans plusieurs familles. En effet, ce n'est quasiment que s'il n'y a qu'un critère de différenciation qu'on peut assurer que les produits n'entreront que dans une et une seule famille. C'est en fait un cas particulier permettant de faciliter, plus tard, l'appartenance des produits aux familles.
Il est évident que plus le nombre de familles sera faible, plus le nombre de temps morts à connaître sera faible. Il faut donc répartir les produits dans le plus petit nombre de familles possible tout en veillant à ce que l'ordre de grandeur des temps morts intra familles reste suffisamment faible par rapport à celui de ceux inter familles.
Il semble tout aussi évident que plus il y aura de critères différenciant les familles, plus la détermination précise des temps morts risque d'être difficile.
De part la démarche suivie, il est nécessaire de déterminer pour chaque produit sa (ses) famille(s) d'appartenance. Pour cela, il faut sélectionner le ou les critères retenus pour la méthode de différenciation.
Dans le cas de critères techniques, il y a sans doute intérêt à ce que les critères retenus soient ceux occasionnant les plus grands temps de setup lors d'un passage d'une valeur à une autre. Les méthodes de différenciation pourront être simples ou complexes. Elles seront souvent simples lorsqu'il n'y aura qu'un critère ou lorsqu'il y en aura plusieurs utilisés dans une série de si ... alors ... sinon ... (hiérarchie de critères).
Par contre, lorsqu'il y aura plusieurs critères "non-hiérarchisables", les méthodes de différenciation devront être plus sophistiquées comme en utilisant une "formule" reprenant une pondération des critères retenus.
Dans ce cas précis, le problème sera de trouver la bonne pondération entre les critères.
Afin de réduire le nombre de familles, il est probable que des produits d'une famille n'auront pas tous exactement les mêmes valeurs pour tous les critères de différenciation. Dès lors, il est nécessaire de déterminer les intervalles à l'intérieur desquels on juge qu'un produit appartient à la famille en question. La largeur des intervalles doit être telle qu'il n'y ait pas trop de famille.
Si les familles sont définies sur bases de critères techniques tels que les temps de setup inter familles soit d'un ordre supérieur aux temps de setup que l'on peut rencontrer intra familles. La définition de "l'ordre de grandeur supérieur" est suffisamment floue pour qu'un second critère soit pris en considération : le nombre de familles. Ce nombre peut aller de 1 à N, où N est le nombre de produits. Dans ces deux cas extrêmes, le résultat sera le même. S'il n'y a qu'une famille, tous les produits seront dedans; il n'y a pas de temps de setup inter familles, mais il y en a énormément intra familles. S'il y a autant de familles que de produits, il n'y a pas de temps morts intra familles mais il y en a énormément inter familles. Dans les deux cas, le problème des temps de setup n'a pas changé.
A ce niveau, les différents problèmes rencontrés se résument comme suit :
Soit, pour les expemples qui suivront, des produits répartissables en quatre familles A, B, C et D.
La seconde phase doit déterminer l'ordonnancement des familles sur base de la minimisation des temps morts inter familles. En général, ces temps morts sont dus à des caractéristiques techniques. Lorsque c'est le cas, la séquence optimale est souvent connue ou tout du moins peut être trouvée par des méthodes de recherche opérationnelle telle que celles appliquées au problème du voyageur de commerce.
Cette séquence correspondra au cycle de production des familles (notion de campagne). Tous les produits d'une famille n'étant pas fabriqués à chaque cycle, on parlera de production de lots de produits appartenant aux familles.
Soit, par exemple, pour les quatre familles (A, B, C et D) un séquencement connu de lots qui est le suivant :
La séquence de fabrication est donc une série répétitive de lots pris dans l'ordre A-B-C-D, B-C-D-A, C-D-A- B ou D-A-B-C, selon le type du premier lot produit.
On peut également concevoir que certaines familles ne doivent pas être produites à chaque cycle mais qu'elles ont leur propre cycle de production.
Soit par exemple la famille C qui n'est produite que tous les 2 cycles.
![]()
Nous allons à présent introduire la notion d'ordres de fabrication (OF).
En fait, le carnet de commande doit être "explosé" en carnet d'OF parmi lesquels seront sélectionnés ceux qui doivent être produits ou commencés dans l'horizon choisi pour être terminés dans les délais souhaités. Un OF est donc l'ordre de fabrication d'un produit dans une certaine quantité avec une date d'échéance au plus tard, dans un lot correspondant à la famille à laquelle appartient ce produit.
La troisième phase devra sélectionner les OF à produire dans un horizon donné et devra déterminer la répartition de ceux-ci dans les lots qui seront produits au court de l'horizon choisi. Intervient ici la notion d'horizon de production. Cet horizon est la période durant laquelle on désire connaître l'ordonnancement des OF. Cet horizon peut être un nombre entier de cycle de familles ou une période de temps couvrant partiellement un ou plusieurs cycles.
Le problème n'est pas de déterminer la durée de l'horizon mais de se fixer une durée de cycle. Celle-ci devra être telle que la proportion qu'aura la somme des temps morts vis à vis de la durée de l'horizon soit raisonnable; sans pour autant choisir une durée trop grande qui risquerait soit d'imposer aux clients des cycles de livraison ayant la même périodicité que le cycle de production, soit de devoir produire à l'avance et donc d'avoir des problèmes de stockage.
Soit la répartition dans les différents lots Ai, Bi, Ci, Di avec i * 1 des OF devant être produits pour l'horizon choisi.

A ce niveau, outre la question de savoir si tel OF de produit appartenant à la famille Y va être produit dans le lot Y1, Y2 ou Yn, d'autres questions vont également se poser :
Ces différentes questions représentent la partie "statique" du problème. La partie dynamique sera représentée par les questions qui vont se poser à l'arrivée de nouvelles commandes prévues ou non.
Enfin la dernière phase sera l'ordonnancement final, c'est-à-dire l'ordonnancement des OF de chaque lot. De nouveau, les critères habituels, tels que les temps de setup, les délais, etc..., seront pris en compte.
Si l'on considère les quatre phases énoncées ci-avant, on s'aperçoit que les deux premières constituent en fait la mise en place du système tandis que les deux suivantes correspondent à l'ordonnancement proprement dit.
Les deux premières phases ne devraient être réalisées qu'une seule fois lors de l'étude préliminaire du nouveau système de gestion de la production. Les familles seraient fixées une fois pour toutes ainsi que l'appartenance des produits à l'une ou l'autre famille. Cette appartenance une fois déterminée serait mémorisée comme étant une caractéristique du produit. Ce n'est que s'il y a "création" de nouveaux produits que l'on devra déterminer leur appartenance à une famille ou à une autre, ou au pire remettre en question les caractéristiques des familles et donc devoir exécuter à nouveau les deux phases.
Ces limites ont été clairement énoncées par Dubois [DUB 86], et sont reprises ci-après.
On peut recenser quatre approches de la conduite de production : l'optimisation, l'analyse sous contraintes, les règles de priorité et la simulation.
L'optimisation aborde le problème de façon très rigoureuse, en recherchant systématiquement les meilleurs ordonnancements au sens d'un critère de fabrication ou de niveau d'en-cours minimums. Le caractère très combinatoire du problème nécessite le recours à des algorithmes sous-optimaux.
L'analyse sous contraintes abandonne l'idée de critères, mais cherche à caractériser des ordonnancements admissibles compte tenu des contraintes de délais et de disponibilité des ressources.
Ces deux approches qui appartiennent au domaine de la recherche opérationnelle, s'appliquent à des problèmes "purs", bien formulés, et d'une structure spécifique. Il est parfois difficile de les appliquer à des ateliers réels car ceux-ci comportent souvent des particularités dont ces approches ne peuvent prendre en compte. Ces particularités peuvent être liées à la nature du processus de fabrication qui induit des contraintes technologiques spécifiques, ou à la présence de ressources de types divers tels que des zones de stockage limitées, ou encore à la présence d'opérateurs humains diversement qualifiés. Ces particularités peuvent rendre inutilisables les résultats obtenus par ces techniques.
L'utilisation de règles de priorité a l'avantage de pouvoir définir des stratégies temps-réel de lancement de production, ainsi que des règles de gestion locales aux machines. Malheureusement, les performances d'une règle de priorité sont difficiles à prédire et s'avèrent très dépendantes des données (des pièces à produire), du processus de production et de l'objectif recherché.
Enfin, la simulation, qui consiste à prédire le comportement de l'atelier avant de prendre les décisions de lancement, est un outil traditionnellement rigide, car reflétant un atelier avec des règles de conduites figées et difficilement modifiables sans mettre en jeu un gros travail de programmation.
Les limites des méthodes traditionnelles ont amené Dubois [DUB 86] à s'intéresser aux systèmes experts afin de contourner ces limites. Ces raisons sont reprises ci-après.
La plupart des langages de programmation utilisés jusqu'à une date récente pour mettre en oeuvre des méthodes d'ordonnancement ou des simulations sont de type procédural. On spécifie des algorithmes, où tous les cas sont prévus, et où les connaissances spécifiques du domaine considéré se mélangent avec les règles qui décrivent la façon d'utiliser ces connaissances (les structures de contrôle). D'où le caractère rigide, peu modifiable et peu adaptatif des algorithmes d'ordonnancement ou de conduite, lequel se marie mal avec l'évolutivité, le manque de fiabilité et la diversité des systèmes de production.
Parmi les divers modes de représentation des connaissances en Intelligence Artificielle, l'approche par règles de production s'est avérée commode dans les applications et s'est fait connaître sous le nom de "méthodologie des systèmes-experts". Les principes de cette technologie et la structure des logiciels qu'elle produit sont bien connus ([LAU 83], [FAR 83]). Dans les systèmes de règles de production, les connaissances factuelles (les faits) et les connaissances opératoires (les règles) sont distinguées de la façon dont l'esprit humain semble le faire. On peut améliorer un système de règles de production à l'aide de modifications locales dues aux propriétés de modularité et de granularité des modes de représentations.
L'utilisation de l'approche "systèmes experts" pour modéliser une stratégie d'ordonnancement ou de conduite semble attrayante, car elle devrait permettre :
En résumé, l'étude portera sur l'ordonnancement de produits répartissables en familles dont les ordres de fabrications sont répartis en lots devant passer sur une machine dans un ordre dicté par un ou des critères techniques, ce qui implique que la séquence minimisant le total des temps de setup peut être assez facilement connue.
Le seul degré de liberté est la taille, et/ou l'existence, des lots dans le cycle.
Le carnet de commandes étant "dynamique", l'existence de lots et les ordonnancements intra lots peuvent être remis en cause lorsqu'une nouvelle commande survient, pour l'insérer dans la séquence globale. Il sera donc nécessaire de trouver comment minimiser les effets de ces insertions.
Pour définir le problème dans des termes plus courants dans la littérature, nous utiliserons ceux définis par Eilon [EIL 78]. Pour lui, un problème d'ordonnancement peut être classifié comme statique ou dynamique, déterministe ou stochastique, simple-produit ou multi-produits, simple-processeur ou multi-processeurs. Selon ces termes, la présente étude porte sur un problème d'ordonnancement statique et dynamique, stochastique, multi-produits, simple-processeur, et nous ajouterons, avec setup-times dépendants de la séquence.
Si l'on prend la terminologie utilisée par une autre classe de problèmes qui recouvre aussi le nôtre, nous sommes également en présence d'un problème de dimensionnement de lots en vue de leur ordonnancement (ELSP : Economic Lot Scheduling Problem). Le domaine utilisé pour résoudre les problèmes de prise de décisions sera celui de l'intelligence artificielle, des systèmes experts et des bases de connaissances. Les figures des pages suivantes permettent de visualiser les processus d'ordonnancement statique et dynamique proposés dans notre démarche.
Au fur et à mesure des lectures, certaines pistes de réflexion se sont révélées. La plupart, ont déjà été citées ci-avant. Nous ne les reprendrons que très brièvement.
Pour les temps de setup, plusieurs pistes sont ouvertes.
La construction de formules mathématiques pourrait permettre d'estimer ces temps de setup en additionnant des temps pondérés représentant la suite des opérations nécessaires pour faire ces setups. La construction de ces formules nécessite l'explicitation du mode opératoire des setups, des différents temps nécessaires pour chaque opération du mode opératoire, et les différentes pondérations de ces temps nécessaires pour un setup entre deux produits donnés.
De plus, s'il n'est pas possible de connaître les valeurs exactes des paramètres, on peut envisager d'utiliser les outils de la logique multivalente, c'est-à-dire ceux des sous-ensembles flous. On peut également envisager d'avoir des intervalles de valeurs, ce qui requerrait les outils des sous-ensembles *-flous. Si maintenant les différents coefficients sont estimés par plusieurs personnes, leur agrégation pourrait se faire sous forme d'expertons.
Ces différentes notions de sous-ensembles flous, *-flous et d'expertons sont également envisageables au niveau de la prise de décision, ou plus exactement pour l'estimation de l'opportunité d'utiliser une règle du système expert dans le cadre d'une décision à prendre.
Avant de prendre une décision, il sera nécessaire de réduire l'espace des solutions afin de n'avoir qu'un minimum de possibilités différentes entre lesquelles choisir. Cette réduction pourrait se faire soit aussi par l'application de règles d'un système expert, soit par recours à des méthodes d'ordonnancement connues. Dans ce cas, une idée à creuser est celle de la transformation de notre problème à une machine en un problème flow-shop ayant la forme suivante :
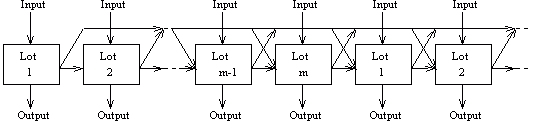
N'oublions pas parmi les pistes possibles la mise en pratique des différents résultats obtenus par les recherches portant sur le problème ELSP.
Enfin, parmi les outils d'intelligence artificielle utilisés dans le cadre de l'ordonnancement, le nom de Prolog revient assez souvent. De plus les nouvelles perspectives permettant de faire de la programmation sous contraintes en Prolog est sûrement une excellente piste à suivre. C'est pourquoi nous nous orientons vers l'utilisation de ce langage.
Lorsqu'un nouveau job de type Y arrive, les questions à se poser sont :
On s'aperçoit, qu'aussi bien du point de vue "statique" que du point de vue "dynamique", le réel problème est celui de la constitution des lots, c'est-à-dire leur remplissage, voire leur existence.
L'assignation d'un job à un lot et son ordonnancement dans ce lot, devront répondre à différents critères, tels que :
Puisque, comme énoncé ci-avant, il serait possible de "laisser tomber" un ou plusieurs lots sur l'horizon choisi, la connaissance des temps de changement d'outils entre familles ne doit pas porter uniquement sur les temps entre familles consécutives dans le cycle connu. En effet, elle doit porter sur tous les temps de changement entre toutes les familles prises deux à deux.
Si certains temps de setup entre certaines familles sont connus, il est rare, dans la pratique, que tous les temps de setup entre toutes les familles prises deux à deux soient connus, ne serait ce même qu'approximativement. Un problème supplémentaire sera donc l'expression et/ou l'estimation de tous ces temps de setup inter familles.
Page : accueil | photos | TaeKwonDo
Auteur : Yves DELVIGNE <yves.delvigne@swing.be>